Current Projects
Agile Hardware/Software Design Methodology
Agile Hardware (AHA)
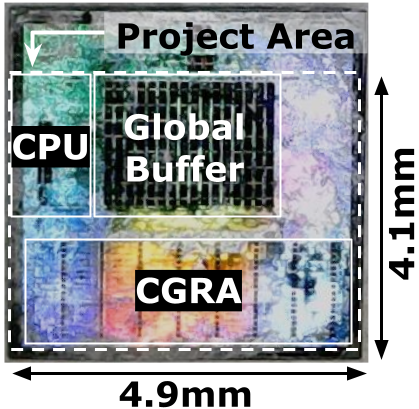 Although an agile approach is standard for software design, how to properly adapt this method to hardware is still an open question. This work addresses this question while building a system on chip (SoC) with specialized accelerators. Rather than using a traditional waterfall design flow, which starts by studying the application to be accelerated, we begin by constructing a complete flow from an application expressed in a high-level domain-specific language (DSL), in our case Halide, to a generic coarse-grained reconfigurable array (CGRA). As our understanding of the application grows, the CGRA design evolves, and we have developed a suite of tools that tune application code, the compiler, and the CGRA to increase the efficiency of the resulting implementation. To meet our continued need to update parts of the system while maintaining the end-to-end flow, we have created DSL-based hardware generators that not only provide the Verilog needed for the implementation of the CGRA, but also create the collateral that the compiler/mapper/place and route system needs to configure its operation. This work provides a systematic approach for designing and evolving high-performance and energy-efficient hardware-software systems for any application domain
Although an agile approach is standard for software design, how to properly adapt this method to hardware is still an open question. This work addresses this question while building a system on chip (SoC) with specialized accelerators. Rather than using a traditional waterfall design flow, which starts by studying the application to be accelerated, we begin by constructing a complete flow from an application expressed in a high-level domain-specific language (DSL), in our case Halide, to a generic coarse-grained reconfigurable array (CGRA). As our understanding of the application grows, the CGRA design evolves, and we have developed a suite of tools that tune application code, the compiler, and the CGRA to increase the efficiency of the resulting implementation. To meet our continued need to update parts of the system while maintaining the end-to-end flow, we have created DSL-based hardware generators that not only provide the Verilog needed for the implementation of the CGRA, but also create the collateral that the compiler/mapper/place and route system needs to configure its operation. This work provides a systematic approach for designing and evolving high-performance and energy-efficient hardware-software systems for any application domain
We used our AHA methodology to design Amber, an SoC with a CGRA accelerator targeting dense linear algebra, published at VLSI 2022. Now, students are working on the next chip, which improves upon our dense applications and adds support for spare tensor algebra. The development process exercises our AHA methodology in several ways including updating the design using our DSLs, adding new compiler support for sparse applications, and doing large design space explorations.
Code: Stanford AHA! Github
Publications:
Canal: A Flexible Interconnect Generator for Coarse-Grained Reconfigurable Arrays
Jackson Melchert, Keyi Zhang, Yuchen Mei, Mark Horowitz, Christopher Torng, Priyanka Raina
To appear in Workshop on Democratizing Domain-Specific Accelerators (WDDSA) at MICRO, October 2022.
2022)
Synthesizing Instruction Selection Rewrite Rules from RTL using SMT
Ross Daly, Caleb Donovick, Jack Melchert, Raj Setaluri, Nestan Tsiskaridze, Priyanka Raina, Clark Barrett, Pat Hanrahan
To appear in Formal Methods in Computer-Aided Design (FMCAD), October 2022.
Improving Energy Efficiency of CGRAs with Low-Overhead Fine-Grained Power Domains
Ankita Nayak, Keyi Zhang, Raj Setaluri, Alex Carsello, Makai Mann, Christopher Torng, Stephen Richardson, Rick Bahr, Pat Hanrahan, Mark Horowitz, Priyanka Raina
Transactions on Reconfigurable Technology and Systems (TRETS), August 2022. Paper
Amber: Coarse-Grained Reconfigurable Array-Based SoC for Dense Linear Algebra Acceleration
Kathleen Feng, Alex Carsello, Taeyoung Kong, Kalhan Koul, Qiaoyi Liu, Jackson Melchert, Gedeon Nyengele, Maxwell Strange, Keyi Zhang, Ankita Nayak, Jeff Setter, James Thomas, Kavya Sreedhar, Po-Han Chen, Nikhil Bhagdikar, Zachary Myers, Brandon D’Agostino, Pranil Joshi, Stephen Richardson, Rick Bahr, Christopher Torng, Mark Horowitz, Priyanka Raina
Hot Chips: A Symposium on High Performance Chips (HotChips), August 2022. Slides, Video
Enabling Reusable Physical Design Flows with Modular Flow Generators
Alex Carsello, James Thomas, Ankita Nayak, Po-Han Chen, Mark Horowitz, Priyanka Raina, Christopher Torng
Design Automation Conference (DAC), July 2022. Paper
Amber: A 367 GOPS, 538 GOPS/W 16nm SoC with a Coarse-Grained Reconfigurable Array for Flexible Acceleration of Dense Linear Algebra
Alex Carsello, Kathleen Feng, Taeyoung Kong, Kalhan Koul, Qiaoyi Liu, Jackson Melchert, Gedeon Nyengele, Maxwell Strange, Keyi Zhang, Ankita Nayak, Jeff Setter, James Thomas, Kavya Sreedhar, Po-Han Chen, Nikhil Bhagdikar, Zachary Myers, Brandon D’Agostino, Pranil Joshi, Stephen Richardson, Rick Bahr, Christopher Torng, Mark Horowitz, Priyanka Raina
IEEE Symposium on VLSI Technology & Circuits (VLSI), June 2022. (Best Demo Paper Award) Paper, VLSI Demo Session
AHA: An Agile Approach to the Design of Coarse-Grained Reconfigurable Accelerators and Compilers
Kalhan Koul, Jackson Melchert, Kavya Sreedhar, Leonard Truong, Gedeon Nyengele, Keyi Zhang, Qiaoyi Liu, Jeff Setter, Po-Han Chen, Yuchen Mei, Maxwell Strange, Ross Daly, Caleb Donovick, Alex Carsello, Taeyoung Kong, Kathleen Feng, Dillon Huff, Ankita Nayak, Rajsekhar Setaluri, James Thomas, Nikhil Bhagdikar, David Durst, Zachary Myers, Nestan Tsiskaridze, Stephen Richardson, Rick Bahr, Kayvon Fatahalian, Pat Hanrahan, Clark Barrett, Mark Horowitz, Christopher Torng, Fredrik Kjolstad, Priyanka Raina
ACM Transactions on Embedded Computing Systems (TECS), April 2022. Paper
An Agile Approach to the Design of Hardware Accelerators and Adaptable Compilers
Ross Daly, Jackson Melchert, Kalhan Koul, Raj Setaluri, Rick Bahr, Clark Barrett, Nikhil Bhagdikar, Alex Carsello, Caleb Donovick, David Durst, Kayvon Fatahalian, Kathleen Feng, Pat Hanrahan, Teguh Hofstee, Mark Horowitz, Dillon Huff, Fredrik Kjolstad, Taeyoung Kong, Qiaoyi Liu, Makai Mann, Ankita Nayak, Aina Niemetz, Gedeon Nyengele, Stephen Richardson, Jeff Setter, Kavya Sreedhar, Maxwell Strange, James Thomas, Christopher Torng, Leonard Truong, Nestan Tsiskaridze, Keyi Zhang, Priyanka Raina
GOMACTech, March 2022. Paper
Creating an Agile Hardware Design Flow
R. Bahr, C. Barrett, N. Bhagdikar, A. Carsello, R. Daly, C. Donovick, D. Durst, K. Fatahalian, K. Feng, P. Hanrahan, T. Hofstee, M. Horowitz, D. Huff, F. Kjolstad, T. Kong, Q. Liu, M. Mann, J. Melchert, A. Nayak, A. Niemetz, G. Nyengele, P. Raina, S. Richardson, R. Setaluri, J. Setter, K. Sreedhar, M. Strange, J. Thomas, C. Torng, L. Truong, N. Tsiskaridze, K. Zhang
Design Automation Conference (DAC), July 2020. Paper, Video, Slides
Automated Codesign of Domain-Specific Hardware Accelerators and Compilers
P. Raina, F. Kjolstad, M. Horowitz, P. Hanrahan, C. Barrett, K. Fatahalian
ASCR Workshop on Reimagining Codesign, March 2021. Paper
Compiling Halide Programs to Push-Memory Accelerators
Q. Liu, D. Huff, J. Setter, M. Strange, K. Feng, K. Sreedhar, Z. Wang, K. Zhang, M. Horowitz, P. Raina, F. Kjolstad
arXiv, May 2021. Paper
A Framework for Adding Low-Overhead, Fine-Grained Power Domains to CGRAs
A. Nayak, K. Zhang, R. Setaluri, A. Carsello, M. Mann, S. Richardson, R. Bahr, P. Hanrahan, M. Horowitz, P. Raina
Design, Automation and Test in Europe Conference (DATE), March 2020. (Best Paper Award Nominee) Paper
Design Space Exploration of CGRA Processing Elements using Peak DSL
Jackson Melchert, Kathleen Feng
Modern AI applications, that typically use neural networks (NNs), have a very diverse set layers and connections. Many networks combine traditional image and video processing operators with convolutional (CONV) and fully-connected (FC) layers to achieve state of the art accuracies. Existing NN accelerators have limited configurability and are optimized to only run CONV and FC layers, and cannot support this growing space of hybrid applications. Coarse-grained reconfigurable arrays (CGRAs) offer an excellent alternative for accelerating these applications. However, coming up with an optimal CGRA design requires a large amount of manual effort. This work creates a framework for automatic design space exploration of processing elements (PEs) in CGRAs. To find interesting PEs, we feed a dataflow graph representation of the application into a frequent subgraph mining algorithm. We then use subgraph merging techniques to allow for the acceleration of multiple subgraphs from the same application or different applications. By tuning which subgraphs are merged, we can explore the design space between more specialized and more general CGRA PEs. Finally, we leverage PEak DSL to generate the PE hardware and a set of rewrite rules that map operators in the dataflow IR to the hardware PEs. This allows the AHA! compiler toolchain to map applications to a CGRA with these new PEs and evaluate efficiency.
Publications:
Automated Design Space Exploration of CGRA Processing Element Architectures using Frequent Subgraph Analysis
J. Melchert, K. Feng, C. Donovick, R. Daly, C. Barrett, M. Horowitz, P. Hanrahan, P. Raina
arXiv, April 2021. Paper
Verified Agile Hardware
Jackson Melchert, Caleb Terrill
In the agile hardware flow, we have created a meta-compiler that enables the automated compilation, mapping, place-and-route, and bitstream generation of Halide applications on whatever CGRA is being generated. This is critical to achieve hardware-compiler codesign. While the current AHA flow can generate a programmable hardware accelerator and its compiler with low design effort, we want to be able to ensure that the application behavior is preserved as it goes through the various stages of the compiler. Specifically, we want to implement formal equivalence checking to show that mapping, place and route, pipelining, and bitstream generation preserve the formal behavior of the application.
This work builds on a software compiler validation technique called translation validation, where transformations in a compiler can be formally proven to not modify the application behavior. These techniques rely on the ability to formal represent and symbolically simulate the program pre- and post-transformation. In our approach, we leverage Satisfiability Modulo Theories (SMT) solvers and the formal representations of our domain specific languages to automatically generate the collateral needed for translation validation. This project will enable us to have confidence that our compiler system does not change the behavior of the applications running on the CGRA.
CGRA Application Pipelining
Jackson Melchert, Yuchen Mei
The clock frequency of applications running on our CGRA designs directly impacts the performance and energy-delay product (EDP) of the accelerator. The maximum frequency of an application depends not only on the maximum frequency of the accelerator, but also on the length of the longest combinational path within the application. This project aims to develop automated tools to identify the critical path within applications, and pipelining techniques to dramatically improve the maximum frequency of applications running on the CGRA. In this project we use several techniques, including pipelining compute units, inserting pipelining registers into the mapped applications, implementing hardware optimizations, modifying application place-and-route algorithms, and inserting registers post-place-and-route.
Systems for Accelerating Virtual and Augmented Reality
Kathleen Feng
Extended reality (XR), which includes virtual and augmented reality, has the potential to have a huge impact on computing. While significant progress in the last few years has helped advance XR technology, the gap between the ideal XR system performance and the current state is still large. One of the difficulties of architecting a high-performance and high-quality XR system is the diversity of kernels and algorithms, which include audio processing, image processing, and tracking. To create a low latency, low power, yet high-quality XR experience, we are taking a system-level approach to XR accelerator design and optimizing many kernels together to reduce overhead. We are first focusing on the machine perception stage and processing on-device sensor information.
Accelerator Architectures Leveraging Emerging Technologies
EMBER
![]()
Luke Upton, Akash Levy
The Efficient Multiple-Bits-per-cell Embedded Resistive RAM (EMBER) macro is a highly configurable non-volatile memory macro capable of up to 4 bits per cell storage with low-power read/write operation at 100 MHz. The block is fully embedded (including decoding, ADCs, DACs, voltage generation, etc.) and has a dedicated digital controller to enable tradeoffs to be made between the number of bits per cell and the bit error rate. EMBER will enable larger on-chip storage for embedded devices, which is critical for combating the “memory wall” associated with off-chip memories.
RRAM Relaxation Modeling
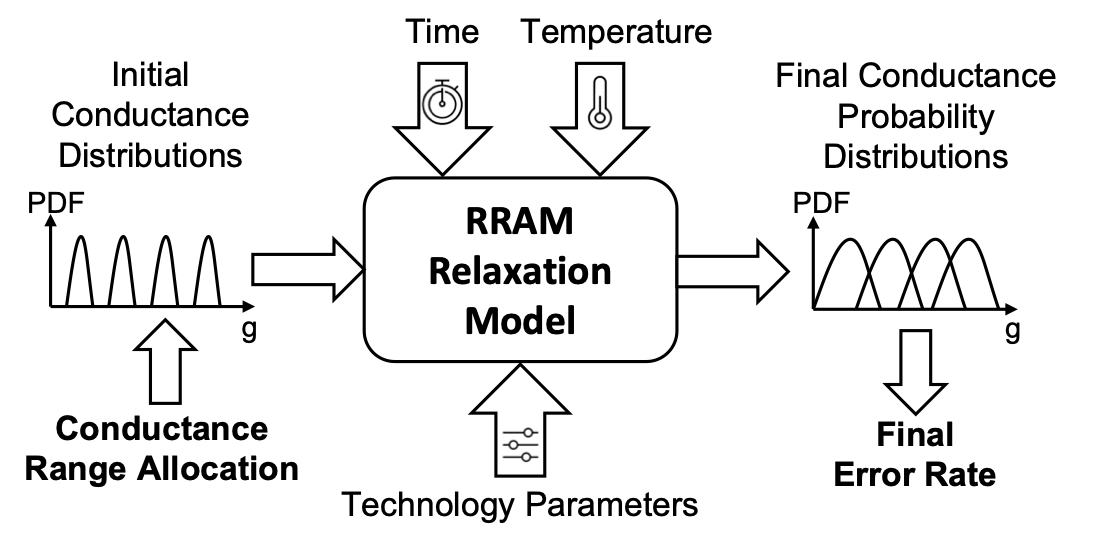
Akash Levy
RRAM undergoes a stochastic resistance relaxation effect after programming that can degrade its reliability. We are interested in creating a simple analytical model that can predict the statistical nature of this effect. Specifically, we would like to have a model that can predict the final conductance probability distributions at an arbitrary time, given a set of initial conductance distributions. Such a model would be invaluable for understanding the multiple-bits-per-cell capability of RRAM in several application contexts, ranging from storage to computation inside memory.
Previous Projects
CHIMERA: Compute (Immersed) in Memory with Embedded Resistive Arrays
 CHIMERA is the first non-volatile deep neural network (DNN) chip for edge AI training and inference using foundry on-chip resistive RAM (RRAM) macros and no off-chip memory. CHIMERA achieves 0.92 TOPS peak performance and 2.2 TOPS/W. We scale inference to 6x larger DNNs by connecting 6 CHIMERAs with just 4% execution time and 5% energy costs, enabled by communication-sparse DNN mappings that exploit RRAM non-volatility through quick chip wakeup/shutdown. We demonstrate the first incremental edge AI training which overcomes RRAM write energy, speed, and endurance challenges. Our training achieves the same accuracy as traditional algorithms with up to 283x fewer RRAM weight update steps and 340x better energy-delay product. We thus demonstrate 10 years of 20 samples/minute incremental edge AI training on CHIMERA.
CHIMERA is the first non-volatile deep neural network (DNN) chip for edge AI training and inference using foundry on-chip resistive RAM (RRAM) macros and no off-chip memory. CHIMERA achieves 0.92 TOPS peak performance and 2.2 TOPS/W. We scale inference to 6x larger DNNs by connecting 6 CHIMERAs with just 4% execution time and 5% energy costs, enabled by communication-sparse DNN mappings that exploit RRAM non-volatility through quick chip wakeup/shutdown. We demonstrate the first incremental edge AI training which overcomes RRAM write energy, speed, and endurance challenges. Our training achieves the same accuracy as traditional algorithms with up to 283x fewer RRAM weight update steps and 340x better energy-delay product. We thus demonstrate 10 years of 20 samples/minute incremental edge AI training on CHIMERA.
Publications:
CHIMERA: A 0.92 TOPS, 2.2 TOPS/W Edge AI Accelerator with 2 MByte On-Chip Foundry Resistive RAM for Efficient Training and Inference
Kartik Prabhu, Albert Gural, Zainab F. Khan, Robert M. Radway, Massimo Giordano, Kalhan Koul, Rohan Doshi, John W. Kustin, Timothy Liu, Gregorio B. Lopes, Victor Turbiner, Win-San Khwa, Yu-Der Chih, Meng-Fan Chang, Guenole Lallement, Boris Murmann, Subhasish Mitra, Priyanka Raina
Journal of Solid-State Circuits (JSSC), January 2022. Paper
CHIMERA: A 0.92 TOPS, 2.2 TOPS/W Edge AI Accelerator with 2 MByte On-Chip Foundry Resistive RAM for Efficient Training and Inference
M. Giordano, K. Prabhu, K. Koul, R. M. Radway, A. Gural, R. Doshi, Z. F. Khan, J. W. Kustin, T. Liu, G. B. Lopes, V. Turbiner, W.-S. Khwa, Y.-D. Chih, M.-F. Chang, G. Lallement, B. Murmann, S. Mitra, P. Raina
Symposium on VLSI Circuits (VLSI), June 2021. Paper (Best Student Paper Award)
In the News:
- New ‘AI-at-the-edge’ smartphone chip lives, and learns, close to home. (Stanford Engineering)
3D CGRA Architecture with NEMS-Based Interconnect
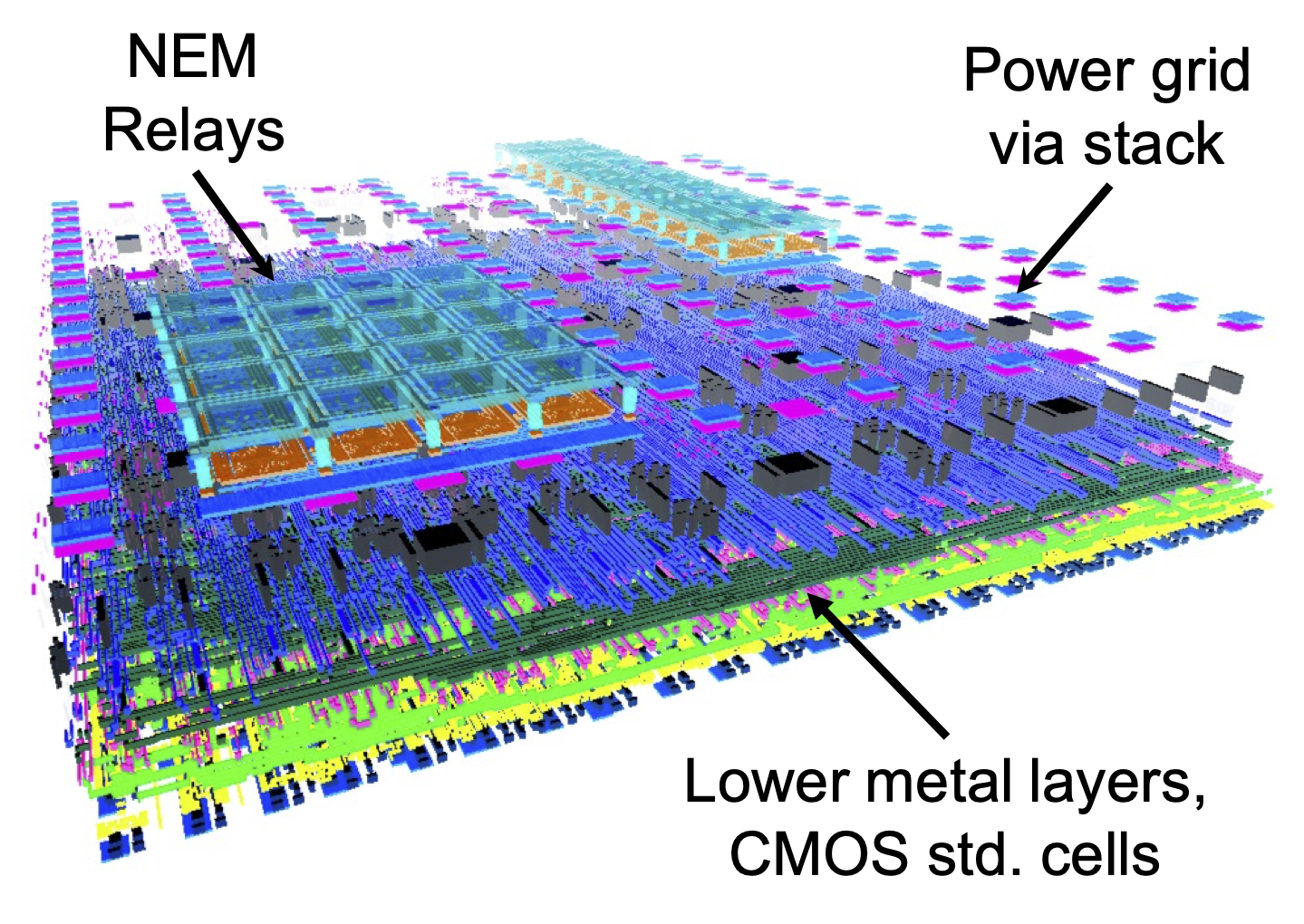 Programmable logic architectures such as FPGAs and CGRAs are extensively used in place of specialized ASICs to accelerate computationally-intensive algorithms. However, when compared with ASICs performing the same function, FPGAs typically have 10-40x lower logic density, 3-4x higher delay, and 5-12x higher dynamic power dissipation. Most of this overhead comes from the configurable interconnect—this work reduces this overhead by using NEMS-based interconnect multiplexers, which can be integrated in 3D on top of silicon CMOS logic.
Programmable logic architectures such as FPGAs and CGRAs are extensively used in place of specialized ASICs to accelerate computationally-intensive algorithms. However, when compared with ASICs performing the same function, FPGAs typically have 10-40x lower logic density, 3-4x higher delay, and 5-12x higher dynamic power dissipation. Most of this overhead comes from the configurable interconnect—this work reduces this overhead by using NEMS-based interconnect multiplexers, which can be integrated in 3D on top of silicon CMOS logic.
Publications:
3-D Coarse-Grained Reconfigurable Array Using Multi-Pole NEM Relays for Programmable Routing
A. Levy, M. Oduoza, A. Balasingam, R. T. Howe, P. Raina
To appear in Integration, the VLSI Journal, October 2022.
Efficient Routing for Coarse-Grained Reconfigurable Arrays using Multi-Pole NEM Relays
A. Levy, M. Oduoza, A. Balasingam, R. T. Howe, P. Raina
IEEE/ACM Asia and South Pacific Design Automation Conference (ASP-DAC), January 2022. Paper
SAPIENS: One-Shot Learning using RRAM-Based Associative Memory
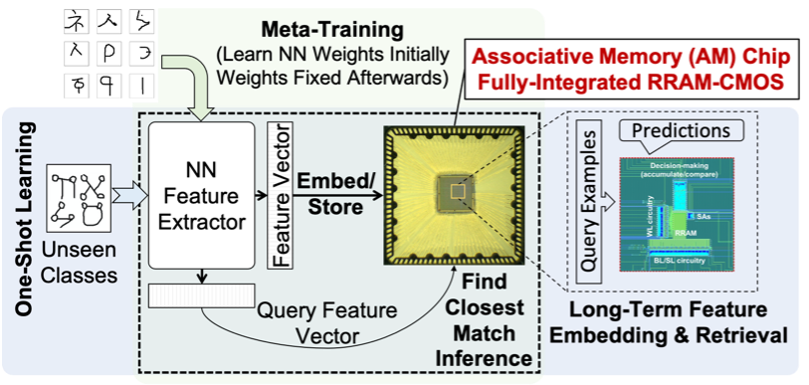 Real-time learning from a few examples (one/few-shot learning) is a key challenge for machine learning systems today. When never-seen-before data is encountered, conventional parametric models like DNNs need to re-learn their parameters via gradient-based learning, often requiring huge amount of data coupled with slow learning iterations. Non-parametric models (like nearest neighbours) do not require any training, but have lower accuracy. Recent research has combined the two to create “memory-augmented” neural networks (MANNs) that can rapidly learn new examples while still performing well on common examples. MANNs consist of a frontend, which is a traditional CNN or RNN, that extracts features from new classes, and a backend associative memory that stores a hashed version of these features. During learning, new features are stored in the memory, and during inference, the feature computed on input data is compared with all the features stored in the memory, and the closest match determines the classification result. This work implements an associative memory with an RRAM-based content addressable memory for area-efficient feature storage and fast feature matching.
Real-time learning from a few examples (one/few-shot learning) is a key challenge for machine learning systems today. When never-seen-before data is encountered, conventional parametric models like DNNs need to re-learn their parameters via gradient-based learning, often requiring huge amount of data coupled with slow learning iterations. Non-parametric models (like nearest neighbours) do not require any training, but have lower accuracy. Recent research has combined the two to create “memory-augmented” neural networks (MANNs) that can rapidly learn new examples while still performing well on common examples. MANNs consist of a frontend, which is a traditional CNN or RNN, that extracts features from new classes, and a backend associative memory that stores a hashed version of these features. During learning, new features are stored in the memory, and during inference, the feature computed on input data is compared with all the features stored in the memory, and the closest match determines the classification result. This work implements an associative memory with an RRAM-based content addressable memory for area-efficient feature storage and fast feature matching.
Publications:
One-Shot Learning with Memory-Augmented Neural Networks Using a 64-kbit, 118 GOPS/W RRAM-Based Non-Volatile Associative Memory
H. Li, W.-C. Chen, A. Levy, C.-H. Wang, H. Wang, P. Chen, W. Wan, H.-S. P. Wong, P. Raina
Symposium on VLSI Technology (VLSI), June 2021. Paper
SAPIENS: A 64-Kbit RRAM-Based Non-Volatile Associative Memory for One-Shot Learning and Inference at the Edge
H. Li, W.-C. Chen, A. Levy, C.-H. Wang, H. Wang, P. Chen, W. Wan, W.-S. Khwa, H. Chuang, Y.-D. Chih, M.-F. Chang, H.-S. P. Wong, P. Raina
IEEE Transactions on Electron Devices (T-ED), September 2021. Paper
NeuRRAM: A Compute-in-Memory Chip Based on Resistive Random-Access Memory
 Realizing increasingly complex artificial intelligence (AI) functionalities directly on edge devices calls for unprecedented energy efficiency of edge hardware. Compute-in-memory (CIM) based on resistive random-access memory (RRAM) promises to meet such demand by storing AI model weights in dense, analogue and non-volatile RRAM devices, and by performing AI computation directly within RRAM, thus eliminating power-hungry data movement between separate compute and memory units. Although recent studies have demonstrated in-memory matrix-vector multiplication on fully integrated RRAM-CIM hardware, it remains a goal for an RRAM-CIM chip to simultaneously deliver high energy efficiency, versatility to support diverse models and software-comparable accuracy. This work is an RRAM-based CIM chip that simultaneously delivers versatility in reconfiguring CIM cores for diverse model architectures, energy efficiency that is two-times better than previous state-of-the-art RRAM-CIM chips across various computational bit-precisions, and inference accuracy comparable to software models quantized to four-bit weights across various AI tasks. (Image credit: David Baillot/University of California San Diego.)
Realizing increasingly complex artificial intelligence (AI) functionalities directly on edge devices calls for unprecedented energy efficiency of edge hardware. Compute-in-memory (CIM) based on resistive random-access memory (RRAM) promises to meet such demand by storing AI model weights in dense, analogue and non-volatile RRAM devices, and by performing AI computation directly within RRAM, thus eliminating power-hungry data movement between separate compute and memory units. Although recent studies have demonstrated in-memory matrix-vector multiplication on fully integrated RRAM-CIM hardware, it remains a goal for an RRAM-CIM chip to simultaneously deliver high energy efficiency, versatility to support diverse models and software-comparable accuracy. This work is an RRAM-based CIM chip that simultaneously delivers versatility in reconfiguring CIM cores for diverse model architectures, energy efficiency that is two-times better than previous state-of-the-art RRAM-CIM chips across various computational bit-precisions, and inference accuracy comparable to software models quantized to four-bit weights across various AI tasks. (Image credit: David Baillot/University of California San Diego.)
Publications:
A Compute-in-Memory Chip Based on Resistive Random-Access Memory
Weier Wan, Rajkumar Kubendran, Clemens Schaefer, Sukru Burc Eryilmaz, Wenqiang Zhang, Dabin Wu, Stephen Deiss, Priyanka Raina, He Qian, Bin Gao, Siddharth Joshi, Huaqiang Wu, H.-S. Philip Wong, Gert Cauwenberghs
Nature, August 2022. Paper
A Voltage-Mode Sensing Scheme with Differential-Row Weight Mapping For Energy-Efficient RRAM-Based In-Memory Computing
W. Wan, R. Kubendran, B. Gao, S. Joshi, P. Raina, H. Wu, G. Cauwenberghs, H.-S. P. Wong
Symposium on VLSI Circuits (VLSI), June 2020. Video, Slides, Demo
A 74TMACS/W CMOS-ReRAM Neurosynaptic Core with Dynamically Reconfigurable Dataflow and In-Situ Transposable Weights for Probabilistic Graphical Models
W. Wan, R. Kubendran, S. B. Eryilmaz, W. Zhang, Y. Liao, D. Wu, S. Deiss, B. Gao, P. Raina, S. Joshi, H. Wu, G. Cauwenberghs, H.-S.P. Wong
International Solid-State Circuits Conference (ISSCC), February 2020. Paper
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
W. Wan, R. Kubendran, C. Schaefer, S. B. Eryilmaz, W. Zhang, D. Wu, S. Deiss, P. Raina, H. Qian, B. Gao, S. Joshi, H. Wu, H.-S. P. Wong, G. Cauwenberghs
arXiv, August 2021. Paper
In the News:
- Stanford engineers present new chip that ramps up AI computing efficiency. (Stanford News)
- New neuromorphic chip for AI on the edge, at a small fraction of the energy and size of today’s computing platforms. (Tech Xplore)
- A New Neuromorphic Chip for AI on the Edge, at a Small Fraction of the Energy and Size. (UC San Diego News Center)
Interstellar: An HLS-Based Framework for Generating and Compiling to Deep Neural Network Accelerators
Xuan Yang, Kartik Prabhu
Deep neural networks require custom accelerators in order to run with high performance and energy efficiency. Several DNN accelerators that have been proposed have very similar properties, with some form of a systolic array and a hierarchy of on-chip buffers. However, designing accelerators from scratch is very expensive in terms of time and resources. To get around this, we have created a generator framework using high-level synthesis that can create DNN accelerator designs with different parameters. In addition to this, we have a tool that performs design space exploration and finds the optimal set of parameters such as array and memory sizes in terms of energy and performance. The tool also finds the best scheduling (loop tiling and ordering) of any neural network layer on the accelerator. In other words, the system doesn’t just generate the accelerator hardware, but also the compiler for it. We are using this system as a class project in EE272, our chip design bootcamp class.
Code: Accelerator Generator, Compiler
Publications:
Using Halide’s Scheduling Language to Analyze DNN Accelerators
X. Yang, M. Gao, Q. Liu, J. Pu, A. Nayak, J. Setter, S. Bell, K. Cao, H. Ha, P. Raina, C. Kozyrakis, M. Horowitz
International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), March 2020. Paper, Video, Abstract
Timeloop: A Systematic Approach to DNN Accelerator Evaluation
Timeloop is an infrastructure for evaluating and exploring the architecture design space of deep neural network (DNN) accelerators. Timeloop uses a concise and unified representation of the key architecture and implementation attributes of DNN accelerators to describe a broad space of hardware topologies. It can then emulate those topologies to generate an accurate projection of performance and energy efficiency for a DNN workload through a mapper that finds the best way to schedule operations and stage data on the specified architecture. This enables fair comparisons across different architectures and makes DNN accelerator design more systematic.
Publications:
Timeloop: A Systematic Approach to DNN Accelerator Evaluation
A. Parashar, P. Raina, S. Shao, A. Mukkara, V. A. Ying, R. Venkatesan, Y. H. Chen, B. Khailany, S. Keckler, J. Emer
International Symposium on Performance Analysis of Systems and Software (ISPASS), March 2019. Paper
Code:
https://github.com/NVlabs/timeloop
A Scalable Multi-Chip-Module-based DNN Accelerator Designed with a High-Productivity VLSI Methodology
 In this work, a scalable deep neural network (DNN) inference accelerator consisting of 36 small chips connected in a mesh network on a multi-chip-module (MCM) was designed. The accelerator enables flexible scaling for efficient inference on a wide range of DNNs, from mobile to data center domains. The chip was implemented using a novel high-productivity VLSI methodology, fully designed in C++ using high-level synthesis (HLS) tools. The 6 square mm chip was implemented in 16 nm technology and achieves 1.29 TOPS/square mm, 0.11 pJ/op energy efficiency, 4 TOPS peak performance on 1 chip, and 128 peak TOPS and 2,615 images/s ResNet-50 inference in a 36-chip MCM.
In this work, a scalable deep neural network (DNN) inference accelerator consisting of 36 small chips connected in a mesh network on a multi-chip-module (MCM) was designed. The accelerator enables flexible scaling for efficient inference on a wide range of DNNs, from mobile to data center domains. The chip was implemented using a novel high-productivity VLSI methodology, fully designed in C++ using high-level synthesis (HLS) tools. The 6 square mm chip was implemented in 16 nm technology and achieves 1.29 TOPS/square mm, 0.11 pJ/op energy efficiency, 4 TOPS peak performance on 1 chip, and 128 peak TOPS and 2,615 images/s ResNet-50 inference in a 36-chip MCM.
Publications:
A 0.32-128 TOPS, Scalable Multi-Chip-Module-based Deep Neural Network Inference Accelerator with Ground-Referenced Signaling in 16nm
B. Zimmer, R. Venkatesan, S. Shao, J. Clemons, M. Fojtik, N. Jiang, B. Keller, A. Klinefelter, N. Pinckney, P. Raina, S. G. Tell, Y. Zhang, W. J. Dally, J. S. Emer, C. T. Gray, S. W. Keckler, B. Khailany
Journal of Solid-State Circuits (JSSC), January 2020. Paper
MAGNet: A Modular Accelerator Generator for Neural Networks
R. Venkatesan, S. Shao, M. Wang, J. Clemons, S. Dai, M. Fojtik, B. Keller, A. Klinefelter, N. Pinckney, P. Raina, Y. Zhang, B. Zimmer, B. Dally, J. Emer, S. Keckler, B. Khailany
International Conference On Computer Aided Design (ICCAD), November 2019. Paper
Simba: Scaling Deep-Learning Inference with Multi-Chip-Module-Based Architecture
S. Shao, J. Clemons, R. Venkatesan, B. Zimmer, M. Fojtik, N. Jiang, B. Keller, A. Klinefelter, N. Pinckney, P. Raina, S. Tell, Y. Zhang, B. Dally, J. Emer, C. T. Gray, B. Khailany, S. Keckler
International Symposium on Microarchitecture (MICRO), October 2019. (Best Paper Award, Top Picks in Computer Architecture Honorable Mentions) Paper
A 0.11 pJ/Op, 0.32-128 TOPS, Scalable Multi-Chip-Module-based Deep Neural Network Accelerator Designed with a High-Productivity VLSI Methodology
B. Khailany, R. Venkatesan, Y. S. Shao, B. Zimmer, J. Clemons, M. Fojtik, N. Jiang, B. Keller, A. Klinefelter, N. Pinckney, P. Raina, S. G. Tell, Y. Zhang, W. J. Dally, J. S. Emer, C. T. Gray, S. W. Keckler
Hot Chips: A Symposium on High Performance Chips (HotChips), August 2019. Slides
A 0.11 pJ/Op, 0.32-128 TOPS, Scalable Multi-Chip-Module-based Deep Neural Network Accelerator with Ground-Reference Signaling in 16nm
B. Zimmer, R. Venkatesan, Y. S. Shao, J. Clemons, M. Fojtik, N. Jiang, B. Keller, A. Klinefelter, N. Pinckney, P. Raina, S. G. Tell, Y. Zhang, W. J. Dally, J. S. Emer, C. T. Gray, S. W. Keckler, B. Khailany
Symposium on VLSI Circuits (VLSI), June 2019. Paper
Automating Vitiligo Skin Lesion Segmentation Using Convolutional Neural Networks
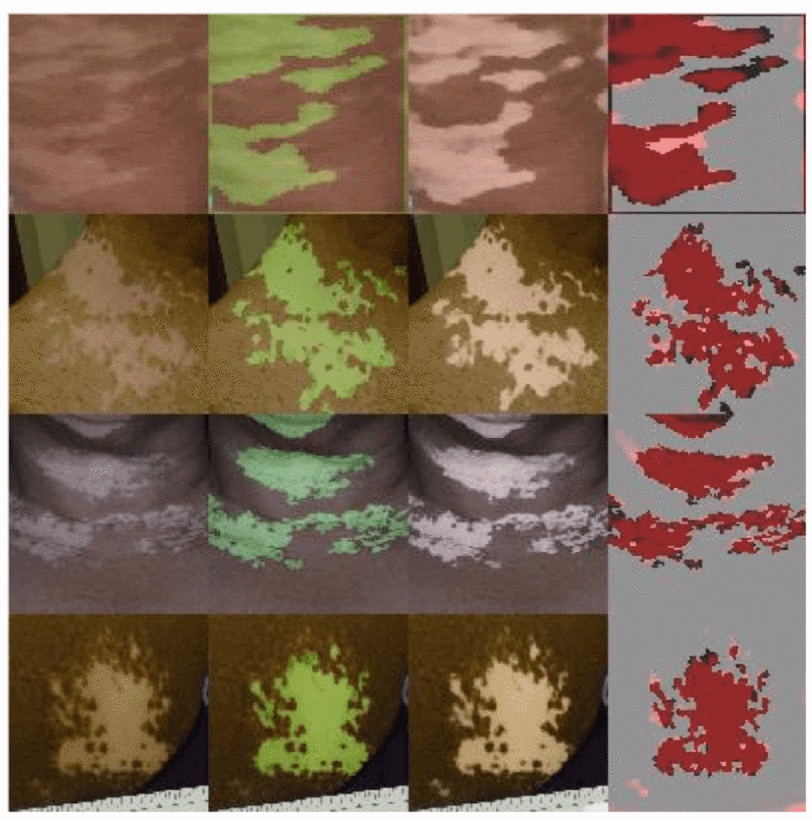 The measurement of several skin conditions’ progression and severity relies on the accurate segmentation (border detection) of lesioned skin images. One such condition is vitiligo. Existing methods for vitiligo image segmentation require manual intervention, which is time and labor-intensive, as well as irreproducible between physicians. We introduce a convolutional neural network (CNN) that quickly and robustly performs such segmentations without manual intervention. We use the U-Net with a modified contracting path to generate an initial segmentation of the lesion. Then, we run the segmentation through the watershed algorithm using high-confidence pixels as “seeds.” We train the network on 247 images with a variety of lesion sizes, complexities, and anatomical sites. Our network noticeably outperforms the state-of-the-art U-Net - scoring a Jaccard Index (JI) of 73.6% (compared to 36.7%). Segmentation occurs in a few seconds, which is a substantial improvement from the previously proposed semiautonomous watershed approach (2–29 minutes per image).
The measurement of several skin conditions’ progression and severity relies on the accurate segmentation (border detection) of lesioned skin images. One such condition is vitiligo. Existing methods for vitiligo image segmentation require manual intervention, which is time and labor-intensive, as well as irreproducible between physicians. We introduce a convolutional neural network (CNN) that quickly and robustly performs such segmentations without manual intervention. We use the U-Net with a modified contracting path to generate an initial segmentation of the lesion. Then, we run the segmentation through the watershed algorithm using high-confidence pixels as “seeds.” We train the network on 247 images with a variety of lesion sizes, complexities, and anatomical sites. Our network noticeably outperforms the state-of-the-art U-Net - scoring a Jaccard Index (JI) of 73.6% (compared to 36.7%). Segmentation occurs in a few seconds, which is a substantial improvement from the previously proposed semiautonomous watershed approach (2–29 minutes per image).
Publications:
Automating Vitiligo Skin Lesion Segmentation Using Convolutional Neural Networks
M. Low, V. Huang, P. Raina
IEEE International Symposium on Biomedical Imaging (ISBI), April 2020. Paper
A Low-Power Accelerator for Real-Time Motion Magnification in Videos
 Many phenomena around us exhibit small motions that are invisible to the naked eye. Recent research has shown that computational amplification can be used to reveal such motions. However, state of the art motion magnification algorithms are computationally intensive and achieve a throughput of only 0.23 frames/s while consuming 10.36μJ energy/pixel on mobile CPUs for FullHD video, which is 4 orders of magnitude higher than what is required for their energy-efficient mobile implementation. This work presents the first low-power accelerator for motion magnification that achieves real-time performance on FullHD video at 30 frames/s, while consuming only around 10nJ of energy/pixel. The chip performs a Riesz pyramid decomposition of each input frame to get local wavelets with amplitude and phase. It temporally filters the phase to isolate the frequencies of interest, spatially smoothes the result to reduce noice, and finally amplifies and reconstructs the output video by inverting the pyramid. We use several techniques to improve efficiency: (1) separable filtering with reordering in the pyramid to reduce multiplies by 5.25x and adds by 3x, and zero-skipping to reduce buffering by 23.3%, (2) compressing the pyramid data to reduce memory bandwidth, (3) detecting active pixels, which are typically less than 50% of the total pixels, from the temporal filter output, and performing magnification for subsequent frames on the active pixels only. As a result, the accelerator (in 40 nm), achieves 130x improvement in performance and 1036x improvement in energy-efficiency over mobile CPUs, enabling, for the first time, efficient integration of motion magnification technology into mobile devices.
Many phenomena around us exhibit small motions that are invisible to the naked eye. Recent research has shown that computational amplification can be used to reveal such motions. However, state of the art motion magnification algorithms are computationally intensive and achieve a throughput of only 0.23 frames/s while consuming 10.36μJ energy/pixel on mobile CPUs for FullHD video, which is 4 orders of magnitude higher than what is required for their energy-efficient mobile implementation. This work presents the first low-power accelerator for motion magnification that achieves real-time performance on FullHD video at 30 frames/s, while consuming only around 10nJ of energy/pixel. The chip performs a Riesz pyramid decomposition of each input frame to get local wavelets with amplitude and phase. It temporally filters the phase to isolate the frequencies of interest, spatially smoothes the result to reduce noice, and finally amplifies and reconstructs the output video by inverting the pyramid. We use several techniques to improve efficiency: (1) separable filtering with reordering in the pyramid to reduce multiplies by 5.25x and adds by 3x, and zero-skipping to reduce buffering by 23.3%, (2) compressing the pyramid data to reduce memory bandwidth, (3) detecting active pixels, which are typically less than 50% of the total pixels, from the temporal filter output, and performing magnification for subsequent frames on the active pixels only. As a result, the accelerator (in 40 nm), achieves 130x improvement in performance and 1036x improvement in energy-efficiency over mobile CPUs, enabling, for the first time, efficient integration of motion magnification technology into mobile devices.
An Energy-Scalable Accelerator for Blind Image Deblurring
 Camera shake is the leading cause of blur in cell-phone camera images. Removing blur requires deconvolving the blurred image with a kernel which is typically unknown and needs to be estimated from the blurred image. This kernel estimation is computationally intensive and takes several minutes on a CPU which makes it unsuitable for mobile devices. This work presents the first hardware accelerator for kernel estimation for image deblurring applications. Our approach, using a multi-resolution IRLS deconvolution engine with DFT-based matrix multiplication, a high-throughput image correlator and a high-speed selective update based gradient projection solver, achieves a 78x reduction in kernel estimation runtime, and a 56x reduction in total deblurring time for a 1920 x 1080 image enabling quick feedback to the user. Configurability in kernel size and number of iterations gives up to 10x energy scalability, allowing the system to trade-off runtime with image quality. The test chip, fabricated in 40nm CMOS, consumes 105mJ for kernel estimation running at 83MHz and 0.9V, making it suitable for integration into mobile devices.
Camera shake is the leading cause of blur in cell-phone camera images. Removing blur requires deconvolving the blurred image with a kernel which is typically unknown and needs to be estimated from the blurred image. This kernel estimation is computationally intensive and takes several minutes on a CPU which makes it unsuitable for mobile devices. This work presents the first hardware accelerator for kernel estimation for image deblurring applications. Our approach, using a multi-resolution IRLS deconvolution engine with DFT-based matrix multiplication, a high-throughput image correlator and a high-speed selective update based gradient projection solver, achieves a 78x reduction in kernel estimation runtime, and a 56x reduction in total deblurring time for a 1920 x 1080 image enabling quick feedback to the user. Configurability in kernel size and number of iterations gives up to 10x energy scalability, allowing the system to trade-off runtime with image quality. The test chip, fabricated in 40nm CMOS, consumes 105mJ for kernel estimation running at 83MHz and 0.9V, making it suitable for integration into mobile devices.
Publications and Talks:
An Energy-Scalable Accelerator for Blind Image Deblurring
P. Raina, M. Tikekar, and A. P. Chandrakasan
Journal of Solid-State Circuits (JSSC), July 2017. (Invited) Paper
An Energy-Scalable Accelerator for Blind Image Deblurring
P. Raina, M. Tikekar, and A. P. Chandrakasan
European Solid-State Circuits Conference (ESSCIRC), September 2016. (Best Young Scientist Paper Award) Paper
An Energy-Scalable Co-processor for Blind Image Deblurring
P. Raina, M. Tikekar, A. P. Chandrakasan
International Solid-State Circuits Conference (ISSCC) Student Research Preview (SRP) Poster Session, February 2016. (2016 ISSCC Student Research Preview Award)
Maxwell: A Reconfigurable Processor for Computational Photography
 Computational photography refers to a wide range of image capture and processing techniques that extend the capabilities of digital photography and allow users to take photographs that could not have been taken by a traditional camera. Since its inception less than a decade ago, the field today encompasses a wide range of techniques including high dynamic range (HDR) imaging, low light enhancement, panorama stitching, image deblurring and light field photography. These techniques have so far been software based, which leads to high energy consumption and typically no support for real-time processing. This work focuses on a hardware accelerator for bilateral filtering which is commonly used in computational photography applications. Specifically, the 40 nm CMOS test chip performs HDR imaging, low light enhancement and glare reduction while operating from 98 MHz at 0.9 V to 25 MHz at 0.9 V. It processes 13 megapixels/s while consuming 17.8 mW at 98 MHz and 0.9 V, achieving significant energy reduction compared to previous CPU/GPU implementations, enabling real-time computational photography applications on mobile devices.
Computational photography refers to a wide range of image capture and processing techniques that extend the capabilities of digital photography and allow users to take photographs that could not have been taken by a traditional camera. Since its inception less than a decade ago, the field today encompasses a wide range of techniques including high dynamic range (HDR) imaging, low light enhancement, panorama stitching, image deblurring and light field photography. These techniques have so far been software based, which leads to high energy consumption and typically no support for real-time processing. This work focuses on a hardware accelerator for bilateral filtering which is commonly used in computational photography applications. Specifically, the 40 nm CMOS test chip performs HDR imaging, low light enhancement and glare reduction while operating from 98 MHz at 0.9 V to 25 MHz at 0.9 V. It processes 13 megapixels/s while consuming 17.8 mW at 98 MHz and 0.9 V, achieving significant energy reduction compared to previous CPU/GPU implementations, enabling real-time computational photography applications on mobile devices.
Publications and Talks:
Reconfigurable Processor for Energy-Efficient Computational Photography
R. Rithe, P. Raina, N. Ickes, S. V. Tenneti, A. P. Chandrakasan
Journal of Solid-State Circuits (JSSC), November 2013. Paper
Reconfigurable Processor for Energy-Scalable Computational Photography
R. Rithe, P. Raina, N. Ickes, S. V. Tenneti, A. P. Chandrakasan
International Solid-State Circuits Conference (ISSCC), February 2013. Paper, Demo
In the News:
- Picture Perfect: Quick, efficient chip cleans up common flaws in amateur photographs. (MIT News)
- Image Processor Makes for Better Photos and Performance (IEEE The Institute)
- MIT imaging chip creates natural-looking flash photos. (Engadget)
- MIT’s new chip promises ‘professional-looking’ photos on your smartphone. (DPReview)
- Improve your smartphone’s photo quality with this chip. (Mashable)
A 3D Vision Processor for a Navigation Device for the Visually Challenged
 3D imaging devices, such as stereo and time-of-flight (ToF) cameras, measure distances to the observed points and generate a depth image where each pixel represents a distance to the corresponding location. The depth image can be converted into a 3D point cloud using simple linear operations. This spatial information provides detailed understanding of the environment and is currently employed in a wide range of applications such as human motion capture. However, its distinct characteristics from conventional color images necessitate different approaches to efficiently extract useful information. This chip is a low-power vision processor for processing such 3D image data. The processor achieves high energy-efficiency through a parallelized reconfigurable architecture and hardware-oriented algorithmic optimizations. The processor will be used as a part of a navigation device for the visually impaired. This handheld or body-worn device is designed to detect safe areas and obstacles and provide feedback to a user. We employ a ToF camera as the main sensor in this system since it has a small form factor and requires relatively low computational complexity.
3D imaging devices, such as stereo and time-of-flight (ToF) cameras, measure distances to the observed points and generate a depth image where each pixel represents a distance to the corresponding location. The depth image can be converted into a 3D point cloud using simple linear operations. This spatial information provides detailed understanding of the environment and is currently employed in a wide range of applications such as human motion capture. However, its distinct characteristics from conventional color images necessitate different approaches to efficiently extract useful information. This chip is a low-power vision processor for processing such 3D image data. The processor achieves high energy-efficiency through a parallelized reconfigurable architecture and hardware-oriented algorithmic optimizations. The processor will be used as a part of a navigation device for the visually impaired. This handheld or body-worn device is designed to detect safe areas and obstacles and provide feedback to a user. We employ a ToF camera as the main sensor in this system since it has a small form factor and requires relatively low computational complexity.
Publications and Talks:
A 0.6V 8mW 3D Vision Processor for a Navigation Device for the Visually Impaired
D. Jeon, N. Ickes, P. Raina, H. C. Wang, A. P. Chandrakasan
International Solid-State Circuits Conference (ISSCC), February 2016. Paper
In the News:
- A virtual “guide dog” for navigation. (MIT News)
- MIT researchers have developed a ‘virtual guide dog’. (boston.com)
- Wearable with 3D camera to guide visually impaired. (Pune Mirror)
More details about Priyanka’s PhD work are on Priyanka’s MIT webpage.